類神經網路 倒傳遞法 back propagation
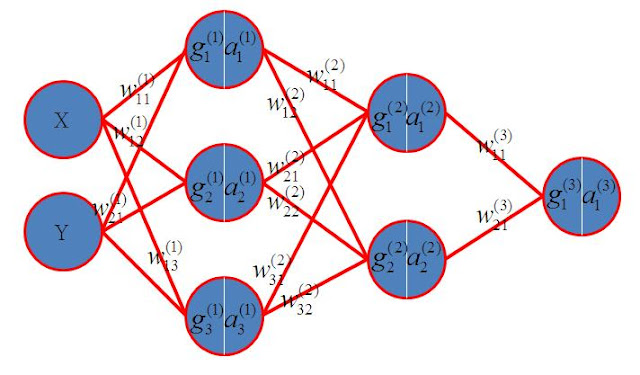
倒傳遞法是一個很舊的東西,但講的類神經網路訓練,就非得提到他。我們也來理解倒傳遞原理。 如上圖,是一個兩個隱藏層的網路。我們的標示法是字母右上角代表第幾層。字母右下角是連線的索引。每個神經原包含 g 跟 a。a是g經過activation function的結果。 如果activation function是sigmoid表示如下, 因為不同網路會選擇不同的activation function因問題與網路會有所不同,我們都以 來表示。 最右邊的神經元是輸出神經原。w為連線的權重。到這裡,我們可以了解當我們在這個網路上輸入X與Y,就會得到一個輸出, 每一次輸出,我們都會想要得到一個差異值,這個差異值代表輸出離我們的目標有多遠。假設我們的目標值為A。那差異就是 我們取平方值可以不用理會差異的正負,1/2是為了微分時方便。有人說不要1/2可以嗎?當然也可以,只是之後推導不方便。我們總要輕鬆的去想一些事情,常數項只要不影響結果,可以想辨法拿掉就拿掉,這是一個技巧。 我們訓練網路,無非就是想要得到各連線的w,用數值的方法,我們可以每次只變化一個權重,觀察輸出往大或小移動。就可以了解這個權重如何影響輸出。把每個權重對輸出的影響都畫成圖,就可以找到讓輸出最接近理想值的權重了。但這樣其實很耗時間。這是今天為什麼需要演算法的原因之一。我們可以寫一個沒有效率的廻圈來算1加到100,也可以像高斯觀察到把數列反序寫,跟原本數列一個一個相加,全都是101,近而產生梯形公式。當然,只要運算能力夠強大,就都不是問題。偏偏人們思考的問題,以目前的科技,運算能力總是不夠強大。 所以我們想了解每一個連線權重對Err的影響,就要用微分。如果我們想知道第二個隱藏層第一個神經原的第一條連線與Err的關係如下 如果我們想知道輸入x的神經原的第一條連線與Err的關係如下 微分也就是斜率,斜率為正,就代表權重變大,會讓Err變大。斜率為負,就代表權重變大Err會變小。所以只要知道每一條連線相對Err的微分,就可以有效率的調整權重的方向了。這樣是不是比數值方法快許多! 接下來我們推導一下 使用 Chain Rule ...