android X 是什麼
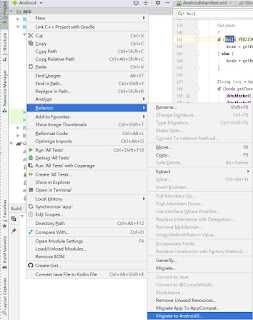
AndroidX 出現一陣子,隨著android版本的更新,看來 GOOGLE 未來是鐵了心要強迫大家用androidX了。到底android X是什麼。 android 開始的時期,是微軟稱霸的時期,所有作業系統都很難有一片天地。在APPLE手機出現之前,智慧手機還是一片安裝微軟系統的陽春機。我們說他陽春是因為軟體的開發者並沒有想象或是去感受一個可攜裝置的未來與使用方式。所以做出來的手機難用至極。這也導致了APPLE IPHONE一出現就席卷了整個世界。我還記得朋友拿iphone3在我面前擺弄的樣子,就像一個小孩發現了好玩的玩具一樣。 此時的google看到了手機市場,也推出了以android為作業系統的手機,這個時期最悲悽的就是NOKIA了。沒有跟上這個潮流,一下子就從天上跌到了海溝裡。在重力加速度的加持下,速度之快,直接深埋在海溝之中。 此時的android也沒有想過,智慧手機的進展會如何。還一堆人在討論,五吋手機太大了,未來一定還會縮小。也一堆人在討論,手機只會越來越大。今天看來,沒有想象力的人們,能討論的只是當下的問題。今天還有人在討論手機未來大小如何嗎?現在討論的是要如何人性化,更好用,更省電,更好一手掌控。 自然在android 3 的時候,為了平版,android加入了fragment功能,讓介面的排列可以更多樣,但是,新的功能如何跟舊的系統相容呢?這就是support library出現的原因了。從這裡每次寫程式都要考慮是要用 android.support.V4.app還是 android.support.V7.appcompat。 物換星移,漸漸的 android1, android2漸漸的看不到市佔了,但舊有的support V4 V7庫裡面還是有往下相容的物件與命名空間。所以也是到了要好好大掃除一下了。因此google 就推出了android X,把所有的物件跟命名空間都重整一下,這樣以後也不用再用V4、V7 這些命名。 主要改變 一 、原本android.support.*,都改成 androidx.* 二、appcompat-v7庫之類都改成appcompat即可,不用帶版號。 如何做出改變 一、目前新版android studio 3.4.2 ,打從新建一個計畫,就直接勾選了使用androidX。所以不用煩腦這個問題。 二、舊程式可以


